|
Listen to this story |
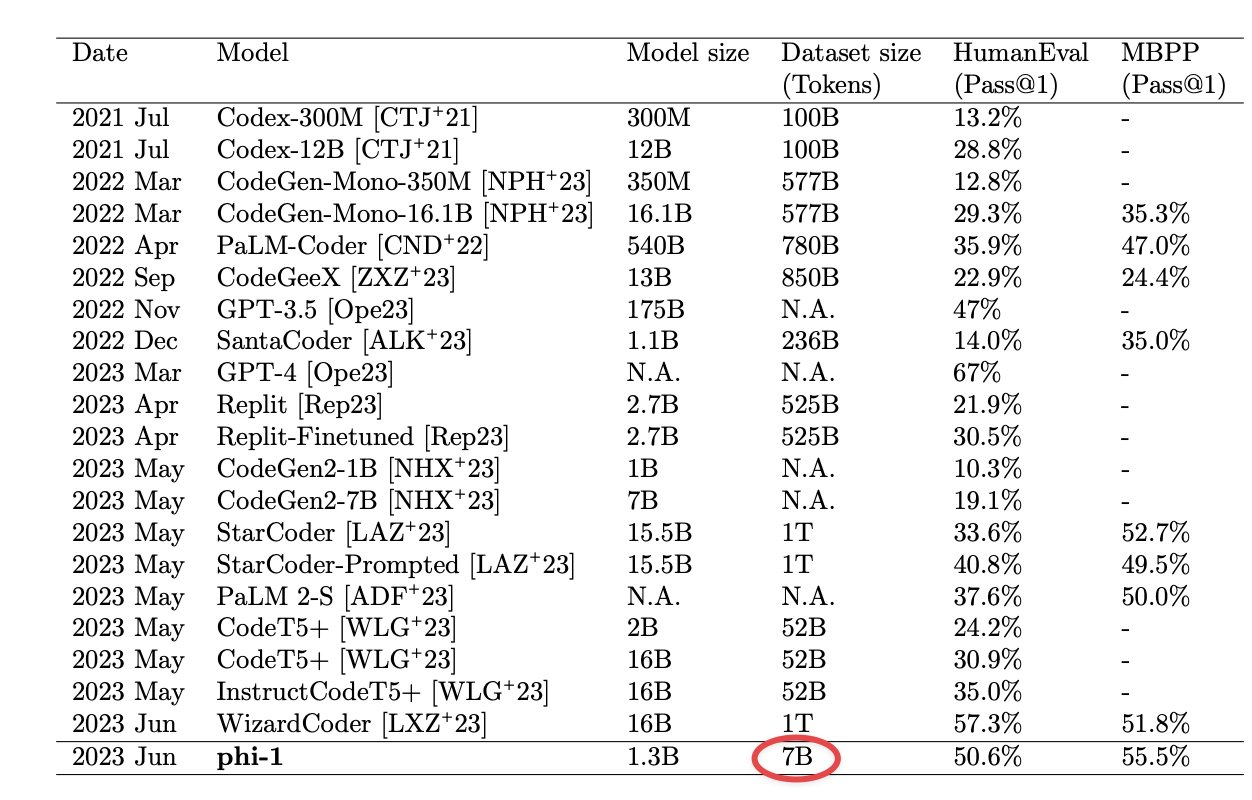
Large language models are getting smaller with great examples like LLaMa and Falcon. Now, Microsoft Research has upped the game with an even smaller model. phi-1 is a transformer based model with just 1.3 billion parameters.
The research paper titled, Textbooks Are All You Need, describes that the model was trained for just four days on 8 A100s with ‘textbook quality’ dataset from the internet with 6 billion tokens, along with synthetically generated textbooks from GPT-3.5 with 1 billion tokens.

Click here to read the paper. The model will be available on Hugging Face soon.
Despite being small in size, phi-1 attained 50.6% on HumanEval and 55.5% on MBPP. There is another even smaller model with just 350 million parameters called phi-1-small that is trained with the same pipeline as the larger one which still achieves 45% on HumanEval.
For comparison, any other model that achieves greater than 50% on HumanEval is 100 times bigger than this with a large dataset size.
Ronen Eldan, one of the co-authors of the paper said that using the textbook quality training data for coding, the results were better than they had anticipated.
In a discussion on HackerNews, a user explains that this would not have been possible without using high quality synthetic dataset that was produced by GPT-3.5. It is clear that training on data from GPT models improves the accuracy and efficiency of the models.
Instead of increasing the size of the model, by improving the quality of the data models are performing way better. This might result in a shift of paradigm in LLM research with focusing more on the architecture and training of models.
Similarly, an open source alternative to GPT-4, Orca, with just 13 billion parameters was also trained on data by GPT-4 and was able to outperform OpenAI’s offering on several benchmarks.
On the other hand, a recent paper – The Curse of Recursion – says that training on other LLMs data actually reduces the quality of output of the new model as it results in data poisoning. This is also called the false promise of imitating proprietary LLMs, as the model also inherits flaws from GPT based models.
Microsoft Releases 1.3 Bn Parameter Language Model, Outperforms LLaMa - Analytics India Magazine
Read More




No comments:
Post a Comment